CRSFashion
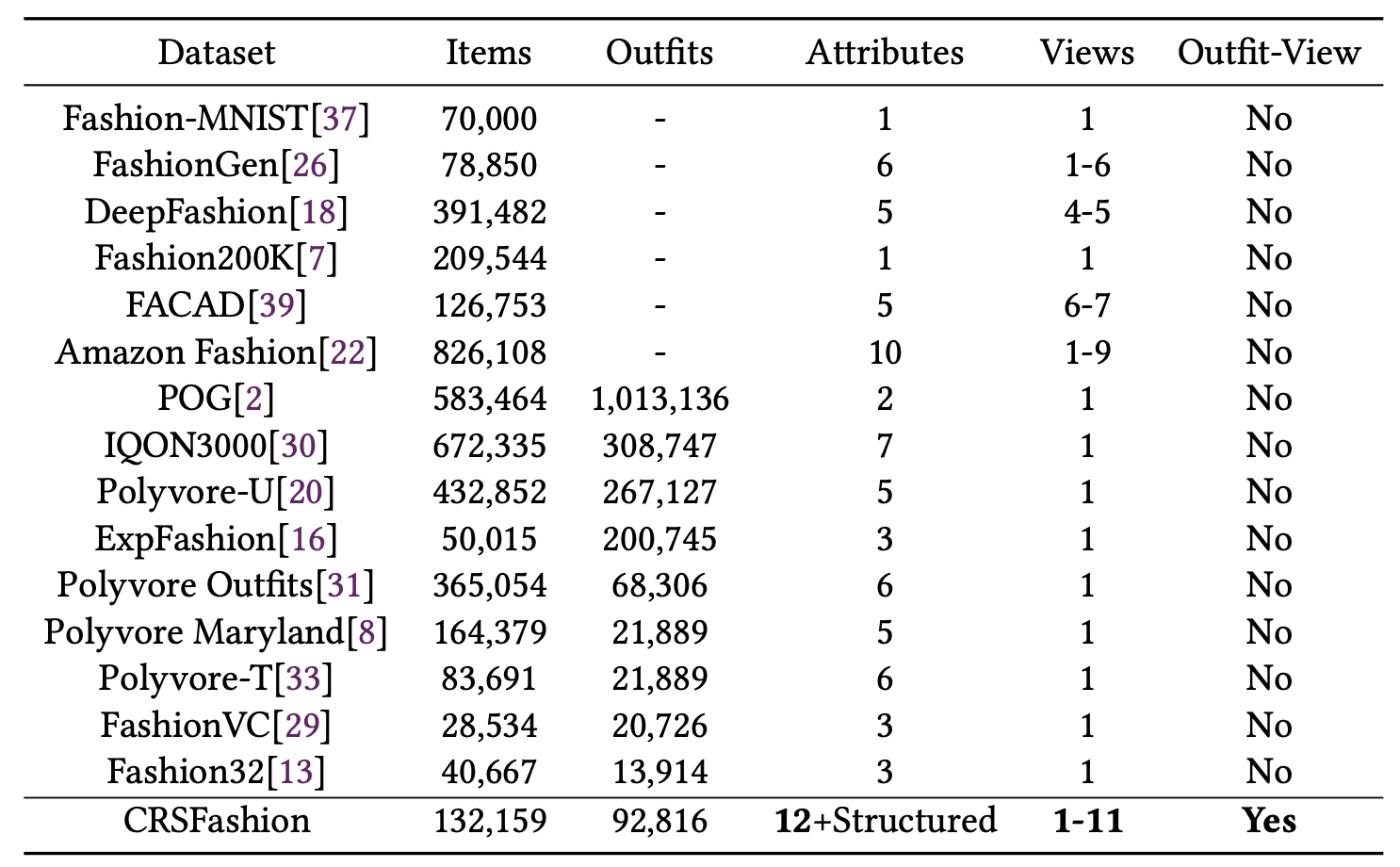
CRSFashion: Capturing Rich Structured Attributes with Multiple Views for Vision-Language Fashion
在电商平台上,服饰产品的种类与数量持续增长,产品通常以图像和文本描述的方式呈现,这使得视觉语言模型(VLM)成为服装任务的天然适配结构。然而,尽管已有许多研究围绕服饰建模、产业应用和基础数据集构建等展开,但如何让 AI 精准理解时尚产品的多维度属性(如材质、版型、搭配)仍然是行业核心挑战。传统方法常忽略文本描述中隐含的结构化语义,难以充分建模商品的丰富信息。为此,我们提出 CRSFashion:一个融合结构化属性与多视角信息的多模态数据集与基准方法框架,显著提升 AI 对时尚内容的理解能力。
核心问题
现有视觉语言模型在时尚场景下主要存在两方面问题:
- 结构化语义缺失:商品描述中隐含丰富的颜色、材质、版型等属性,但模型无法显式感知。
- 视图表达不足:依赖单一主图难以捕捉商品多角度特征与搭配上下文。
CRSFashion 方法概述
1. 结构化属性建模
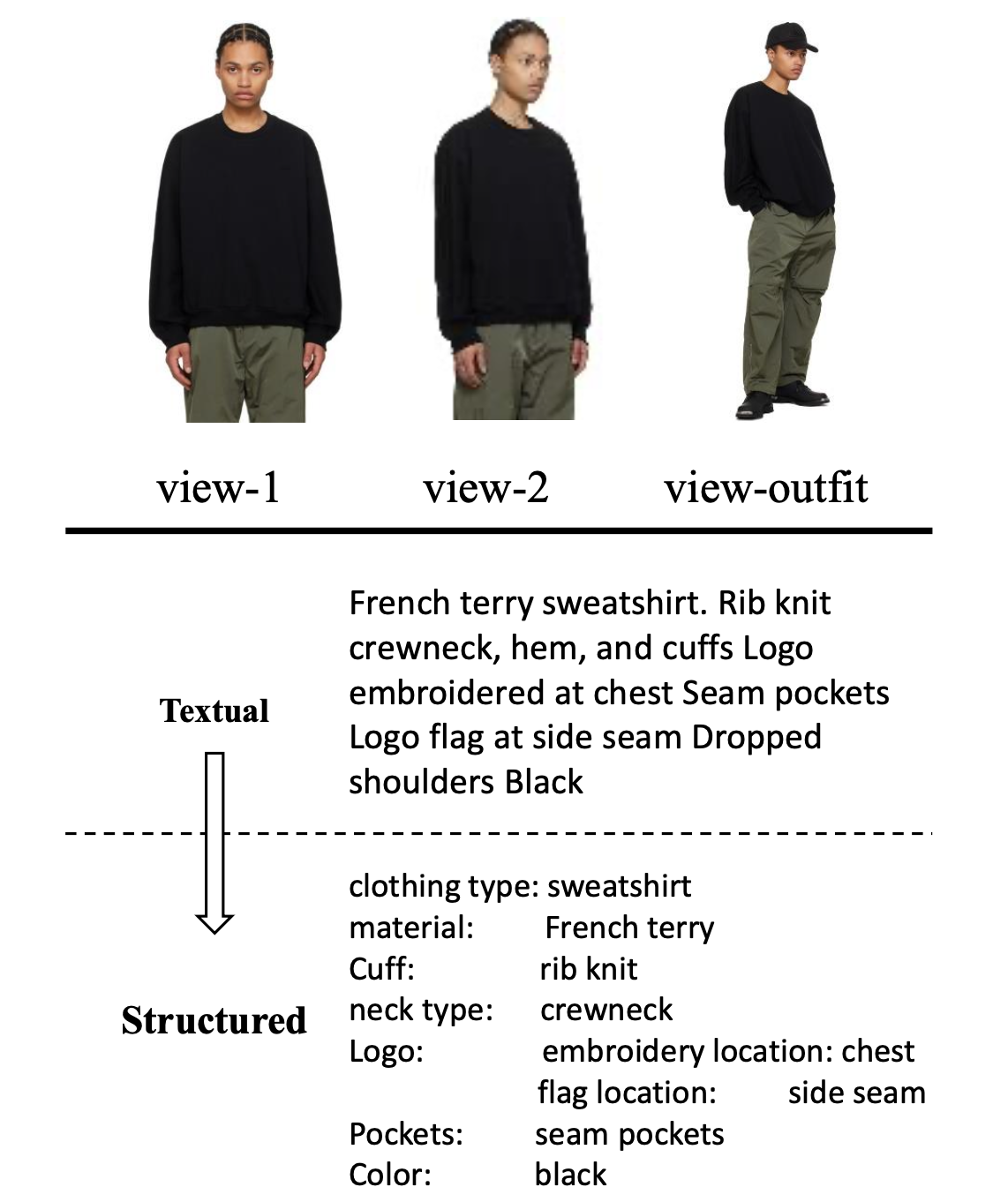
在 CRSFashion 中,结构化属性的构建不仅仅是对服饰特征的简单枚举,更是对时尚语义进行系统建模的过程。为了全面捕捉时尚领域中多样化且具备专业语义的属性信息,我们对多种时尚数据源(如多个服饰电商平台和已有数据集)中的商品文本描述进行深入分析,并从语义角度出发,将丰富的属性划分为五种基础类型与一种嵌套类型,如图所示:

通过这种系统性的属性类型划分方式,CRSFashion 能够更加精准地表示商品在风格、结构、材料、数量等多个维度的信息,为下游多模态建模提供了细粒度、结构化且语义明确的属性支撑。这不仅提升了模型对服饰语义的理解能力,也增强了在时尚任务中的可解释性与泛化能力。
2. 结构化属性指令模板设计
为了帮助大语言模型更好地理解服装商品的核心语义,我们构建了结构化属性体系,并设计了指令模板,引导模型从文本描述与图像信息中提取关键服饰要素,如颜色、材质、版型等。这种模板化设计不仅规范了输入形式,还显著提升了模型在多模态服装理解和下游任务中的表现。
3. 多视角图像对齐建模
为克服单一视图在细节捕捉和整体风格建模上的局限,CRSFashion 引入多视角图像对齐机制。我们整合每件商品的多张图片,包括主图、侧面图、细节图等多个角度,以及完整的搭配图(Outfit View),以丰富视觉表征的深度与广度。通过这些多样化视图,模型能够更全面地理解商品的面料纹理、剪裁结构与搭配风格,从而提升在细粒度识别、商品检索和搭配推荐等多模态任务中的表现。
数据集构建流程
CRSFashion 从 SSENSE 等平台采集并清洗了 13 万余件商品数据,覆盖 52 万余张图像,提供图文对齐及搭配上下文信息。
- 商品数量:132,159
- 图像总数:528,534(含多视角与搭配视图)
- 每个商品平均视图数:约 4 张
- 类别:覆盖男/女装全品类
为构建一个高质量、多模态的时尚数据集,CRSFashion 设计了系统性的三阶段流水线,包括数据采集与清洗、结构化属性提取与融合、多模态对齐与验证。该流程不仅涵盖来自电商平台的图文信息采集,还引入了多视图图像抓取、图文属性协同提取、融合标准化命名与质量审校等关键模块。整个 pipeline 的核心目标是确保每个商品实例都具备结构化、可控、对齐良好的图文信息,最大化数据的语义密度与模型可学习性,为下游任务如检索、分类与搭配预测提供了坚实数据基础。
第一阶段:数据采集
CRSFashion 的数据采集与清洗流程围绕 SSENSE 电商平台展开,旨在构建一个涵盖多视角图像与结构化文本信息的高质量多模态时尚数据集。首先,通过自动化脚本从商品详情页抓取原始图像和文本信息,包括主图、细节图、侧视图以及搭配图等多个视角,同时同步获取商品名称、描述、价格、材质等文本字段。原始XML文件会被直接存储至云端,确保其不可变性,便于后续任务的重跑和版本追踪。
在数据清洗阶段,对原始内容进行去重、纠错与异常过滤,处理图像缺失、文本乱码、字段缺省等常见问题。特别是对重复商品、模糊图像、无关搭配图等噪声数据进行了剔除。此外,为保证图文内容的结构统一性,还对文本字段进行了标准化处理,例如对品牌与品类字段进行规范映射,并通过人工辅助审核机制进一步提升数据的一致性与准确性。该阶段为后续的属性建模、多模态融合等任务奠定了坚实的数据基础。
第二阶段:结构化属性抽取
在 CRSFashion 的结构化属性抽取流程中,我们充分发挥大语言模型(LLM)在理解与生成结构化信息方面的能力,设计了一套“指令驱动 + 多轮推理”的属性抽取机制,以实现高质量的图文属性建构。
首先,我们使用 基于模式匹配的预处理方式,从商品文本中直接提取一些显性属性,如性别、服装类型等。这些属性在电商文本中通常具有稳定格式,因此可以通过关键词匹配和正则表达式规则高效提取,并作为结构化建模的初始输入。
接下来,CRSFashion 构建了三轮基于 LLM 的结构化属性抽取流程。在第一轮中,我们针对原始商品描述文本($DESCRIPTION)构建统一的提示模板,分别输入至两个语言模型(gpt-o3-mini 和 DeepSeek-V3)。这些模板旨在引导模型从非结构化描述中识别出颜色、材质、版型、细节等属性,并以预定义格式返回。该阶段的目标是生成 两个候选的结构化属性集合,分别来自两个模型的独立推理结果。通过这种“双通道”设置,我们可以最大程度减少单一模型误判所带来的风险,同时获得更全面、互补的属性视图。如图所示:

在结构化属性抽取流程的最后一步中,CRSFashion 进一步引入更强大的大语言模型 —— GPT-4o,以提升属性抽取的准确性与一致性。
具体来说,在前一阶段,系统已通过两个不同的 LLM(如 gpt-o3-mini 与 DeepSeek-V3)生成了两个候选的结构化属性版本。这两个版本虽然各自具备一定的语义覆盖和格式化能力,但在细节、用词、属性归类等方面可能存在差异。
为此,CRSFashion 设计了一条指令模板,将两个候选版本作为输入,通过调用 GPT-4o 对其进行融合与重构。在该指令中:STRUCTURED_ATTRIBUTES_1 和 STRUCTURED_ATTRIBUTES_2 分别表示来自前两步的候选属性结果;GPT-4o 需要参考这两个候选属性,进行合理的判断、归纳与抽象,生成最终的结构化属性。

这一过程相当于在多个语言模型之间构建共识,借助 GPT-4o 强大的推理能力与语言理解能力,整合前两步的结果,进一步注入时尚领域的知识,提升抽取结果的完整性、准确性与结构规范性。最终生成的结构化属性更加精炼、稳定,并能更好地服务于后续的多模态建模任务。
第三阶段:多视角与搭配图像的结构化分组
在多视角图像提取阶段(Multi-views Extraction)中,CRSFashion 为了更精准地建模服装的视觉语义,对原始图像数据进行了手工分组与划分,以确保多模态信息的结构清晰、语义明确。
具体而言,研究人员首先针对每个商品采集到的一组图像进行整理,将其划分为两个部分:
- 商品多视角图像(multi-view images):这部分图像展示的是同一时尚单品在不同视角、细节、场景下的表现,例如正面、背面、侧面、细节特写等,有助于模型更全面地理解商品的材质、轮廓与结构。
- 搭配图像(outfit view):这部分图像体现了该商品在实际搭配场景中的应用,通常是模特穿着该单品与其他服饰组成完整穿搭的照片。这为模型提供了上下文感知能力,使其能够理解商品在穿搭场景中的功能与风格定位。
通过这种分组,CRSFashion 不仅保留了细粒度的产品信息,还引入了场景化的搭配语境,有效增强了数据的多模态表示能力,为后续的搭配推荐、视觉理解等任务提供了坚实的基础。
数据集分析与统计
CRSFashion 旨在为服装属性理解与搭配建模等下游任务提供高质量的数据支持。该数据集共包含 132159 件时尚单品,对应 528534 张高质量图像,图像分辨率为 960 × 640,并计划后续发布更高分辨率版本以供研究使用。图像类型包括主视图、细节图以及搭配图,构成多视角视觉输入。
在属性设计方面,每个商品均标注了 12 个基础属性,并进一步通过结构化方式标注了细粒度的时尚语义属性。与现有数据集相比,CRSFashion 独特地引入了如设计师信息、搭配图、搭配商品以及三级类目体系等信息,以构建更具表达力的多模态输入。
为了增强模型对性别语境下时尚属性的理解,CRSFashion 特别设计了 基于性别的类目体系,共计包含 184 个品类,下图展示了前 30 个高频类别的分布情况。此外,数据集中还补充了 11,062 件与生活场景相关的时尚产品,以增强类目的多样性与泛化能力。

在数据划分上,CRSFashion 采用标准的 8:1:1 的训练、验证与测试划分比例,确保任务评估的一致性与可复现性。每个样本均包含结构化的属性标注与图像信息,覆盖多视角、多语义的丰富时尚内容,适用于包括图文匹配、多标签分类、搭配推荐等多种研究任务。
为了进一步支持搭配推荐等服装组合类任务,我们从原始的 CRSFashion 数据集中提取了搭配视角相关的样本,构建了 CRSFashion-outfit 子集。该数据集基于已有的搭配商品(outfit products)字段构建,最终包含 92816 组搭配样本。相较于现有的 outfit 类任务数据集,CRSFashion-outfit 的优势在于:每一件参与搭配的单品不仅具备 完整的结构化属性信息(包括 12 个基础属性与语义属性),还具备主图、多视图和搭配图等多模态视觉输入,如图所示:
在评估任务设计上,我们参考主流 outfit fashion 工作的数据构建方式,构建了针对 outfit 推荐与理解任务的评估基准。数据集被划分为训练集、验证集与测试集,遵循 8:1:1 的标准比例,以保障任务评估的一致性与公平性。
为更直观地展示 CRSFashion 数据集的特性,我们从中选取了三个具有代表性的样例,如下图所示。每个样例展示了该商品的 基础属性 与 结构化属性,以及其多视角图像输入。可以明显看到,属性信息层次清晰、语义明确,多视角图像也有助于丰富视觉理解,体现了本数据集在服装语义建模与多模态理解方面的显著优势。

实验与评估
为了验证所提出的 CRSFashion 方法及其构建的高质量数据集在多模态服装任务中的有效性,我们设计了两类代表性实验任务:跨模态检索与类别识,并分别在不同规模的模型与多种推理设置下进行测试。
跨模态检索任务
该任务旨在评估模型在图文理解与匹配方面的能力,包括两个子任务:
- 图搜文:根据输入图像检索与之匹配的文本描述;
- 文搜图:根据输入文本描述检索对应图像。
我们采用标准检索指标 R@k 进行评估,即目标是否出现在前 k 个检索结果中。实验设置上,我们使用 FashionSAP 的公开代码与评估流程,并将预训练数据替换为 CRSFashion 数据集,从而在 FashionGen 测试集上进行公平对比,相关结果如图所示:

在实验中我们构造了两种不同数据配置:
- CRSFashion_textual:仅使用产品原始文本描述作为语言模态输入;
- CRSFashion_structured:在文本基础上引入结构化属性信息;
可以看出 CRSFashion 在两个检索任务中均取得了显著提升。即使仅使用原始文本描述,相较于已有方法也能带来接近 3% 的 R@k 提升;进一步加入结构化属性与多视图图像后,性能提升更为明显,验证了我们在结构化表示与多视角建模方面的设计优势。
类别识别任务
类别识别任务旨在根据一件服装产品的图像和文本描述,识别其所属的具体服装品类。该任务更关注模型对于多模态输入中类别信息的理解能力。
我们从完整的 CRSFashion 数据集中构建了用于该任务的专用子集。为了与现有工作保持一致并保证公平性,我们移除了与生活环境相关的产品,仅保留真实穿着类服饰样本。最终划分得到训练集 96800 条、验证集 12109 条和测试集 12188 条。
为全面评估 CRSFashion 方法在该任务中的有效性,我们在两类模型上进行了实验:
- 轻量级多模态模型:包括 ALBEF-14M 与 FashionSAP,它们均需要在训练集上进行微调;
- 大模型: Deepseek-vl-1.3b-chat 与 Deepseek-vl2-small,采用零样本或少样本推理方式评估泛化能力。
实验设计中,我们对比了以下两种输入方式:
- Textual:仅使用产品原始文本描述;
- Structured:引入结构化属性,并按照 Listing 1 所示指令模板组织输入内容。
对于轻量模型,Structured 版本不使用 $INSTRUCTION 模板,而直接拼接结构化信息;而对于 VLLMs,则使用完整的自然语言指令模板,具体示例如图所示:。

实验结果如表所示,CRSFashion 数据集在两类模型中均展现出显著的性能提升,特别是在 F1 分数和准确率两个核心指标上。引入结构化属性与明确语义指导后,模型对类别的理解与识别更为准确,进一步验证了我们在属性组织与多模态融合方面设计的有效性。

数据集评估
为了进一步验证所提出的 CRSFashion 数据集在下游任务中的适用性与优越性,本节采用 Text Modified Image Retrieval(TMIR) 任务对比评估 CRSFashion 与经典服装多模态数据集 FashionGen 的表现。在实验过程中,严格控制变量,确保预训练阶段仅使用 FashionGen 或 CRSFashion 数据集,其他设置保持一致,从而客观评估数据集本身对模型性能的提升作用。
TMIR 任务旨在检索出同时满足参考图像的基本视觉特征与文本描述中给出的修改语义。该任务更贴近用户在电商场景中的真实行为,如“我喜欢这件衣服的风格,但希望它是红色的”——系统需找到与原图像相似、同时满足“红色”这一新需求的目标图像。
我们在 FashionIQ 数据集上进行该任务评估。值得注意的是,FashionIQ 并未被用于任何预训练阶段,仅作为评估集使用。我们分别使用 FashionGen 和 CRSFashion 进行模型的预训练,并在 FashionIQ 上进行 TMIR 测试,采用与 FashionFormer 一致的设置与评价指标。
如下表所示,使用 CRSFashion 预训练的模型在 TMIR 任务中表现出明显优势,尤其是在引入结构化属性后,在多个评价指标(如 R@10)上均取得更高得分。这一结果充分表明,CRSFashion 数据集中明确组织的结构化属性和多视角图像设计,能有效增强模型对服饰语义的理解与推理能力,从而提升在复杂多模态检索任务中的泛化表现。

搭配兼容性评估
为了进一步验证 CRSFashion 在服装搭配任务中的适用性,我们在多模态搭配任务 Outfit Compatibility(OC) 上进行实验评估。该任务的目标是判断一组给定的服饰单品是否在视觉与语义上构成“协调搭配”,即是否属于一种“兼容”的穿搭组合。
本实验基于我们提出的 CRSFashion-outfit benchmark 数据集进行。为了更全面地评估模型的泛化能力,我们从数据集中构建了两个子集:
- Overlap 子集:训练集、验证集和测试集之间的产品存在重叠,适合评估模型在已知风格上的拟合能力;
- Disjoint 子集:训练集、验证集和测试集中的产品完全不重叠,用于更严格地评估模型对结构化属性与搭配逻辑的泛化能力。
我们对比实验中采用了基线方法 FashionSAP,并对其进行修改,使其支持多模态搭配输入。此外,我们进一步引入结构化属性,并根据 Listing 1 所示的指令格式对输入内容进行统一处理。
实验结果如下表所示。我们重点报告了在 Disjoint 子集上的结果,以评估模型在“从未见过的单品”上的搭配能力表现。实验表明,引入结构化属性显著提升了搭配兼容性识别的准确性,这不仅验证了 CRSFashion 方法的有效性,也为未来多模态服饰搭配建模提供了一个新基线。

该实验进一步证明:结构化的语义注入和多视角设计能显著提升多模态模型在复杂搭配任务中的理解与判断能力。